
Accuracy != Alpha
The most accurate LLM in our Intelligent Earnings benchmark didn't make the most money in a simple trading test. One of the least accurate one did.

It’s often a good policy to something out in the world to see what happens.
We put our Intelligent Earnings Benchmark into the world a few weeks back and got clear feedback: The world wants backtests. We obliged. Now we have four quarters of LLMs predicting changes in forward estimates for public companies.
Our backtests taught us several things:
GPT was the king of stock estimate prediction, although this may change as models continue to improve. The GPT model family outperformed all other models on average across our entire test period as well as ranking first or second for each individual period.
Closed-source models consistently lead for most performance metrics. Open-source models are often a tier below closed source models on most metrics.
Accuracy on prediction doesn’t necessarily mean the best investment performance. Some of the middling performers on accuracy were the best in actual alpha generation when trading the picks.
Accuracy
As a reminder, the Intelligent Earnings Benchmark tests the ability of LLMs to predict the movement of future estimates of public companies across:
Raw prediction direction (up, down, flat)
Magnitude of change (small, medium, large)
GPT was the best ranked model in all the backtest/live quarters except Q325. Interestingly, in that quarter GPT 5.1 was the latest model with a knowledge cutoff date prior to the period. That model is two versions older than the current GPT 5.5. Gemini 3.1 Pro won most accurate model in Q325, which is the current version of Gemini. Anecdotally, we tend to see more recent models performing better than older release models.
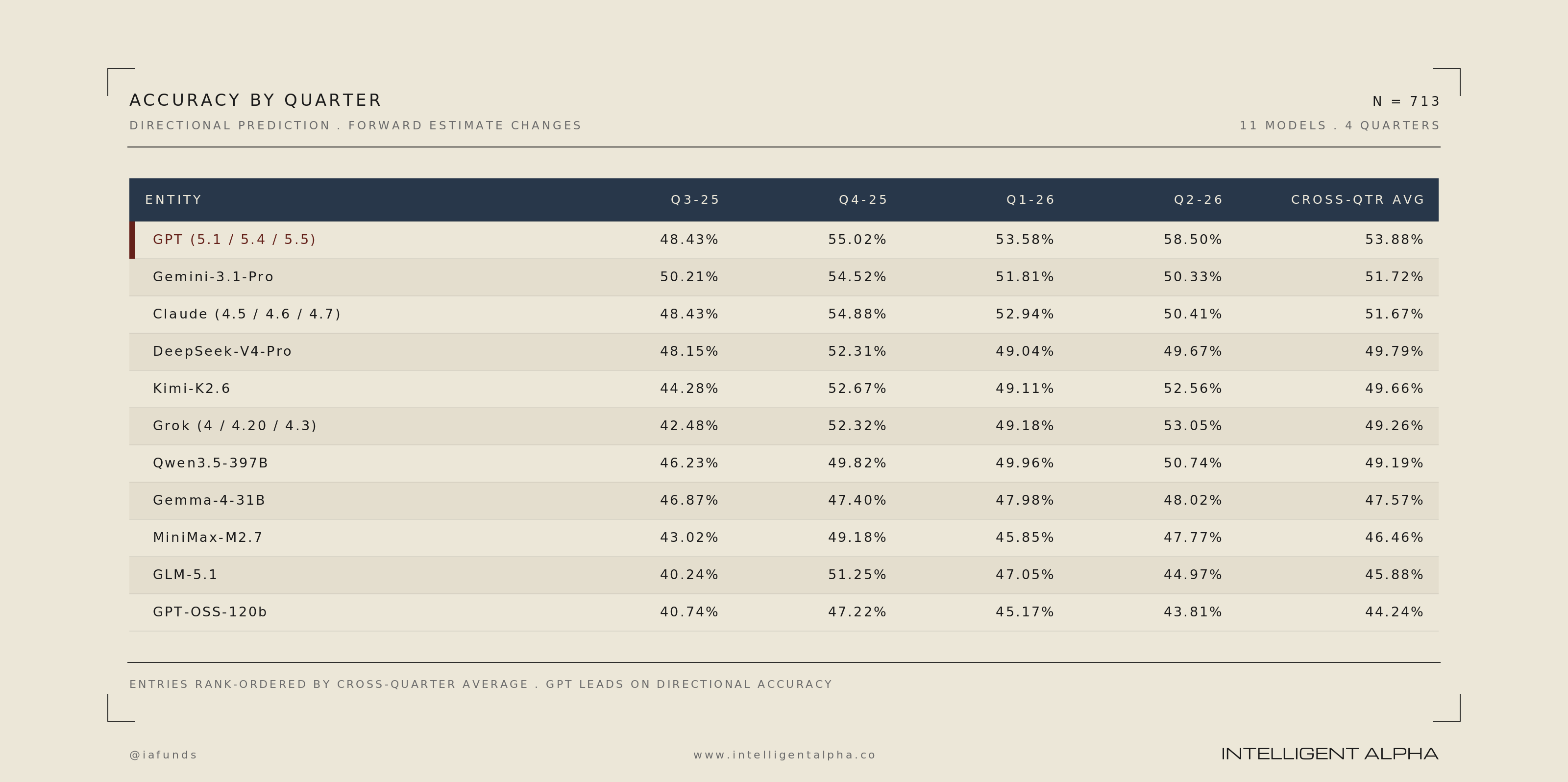
GPT was also the best model at predicting the correct magnitude of forward estimate changes (e.g. up small, up large, down small, etc). Only Gemini beat GPT again in Q325.
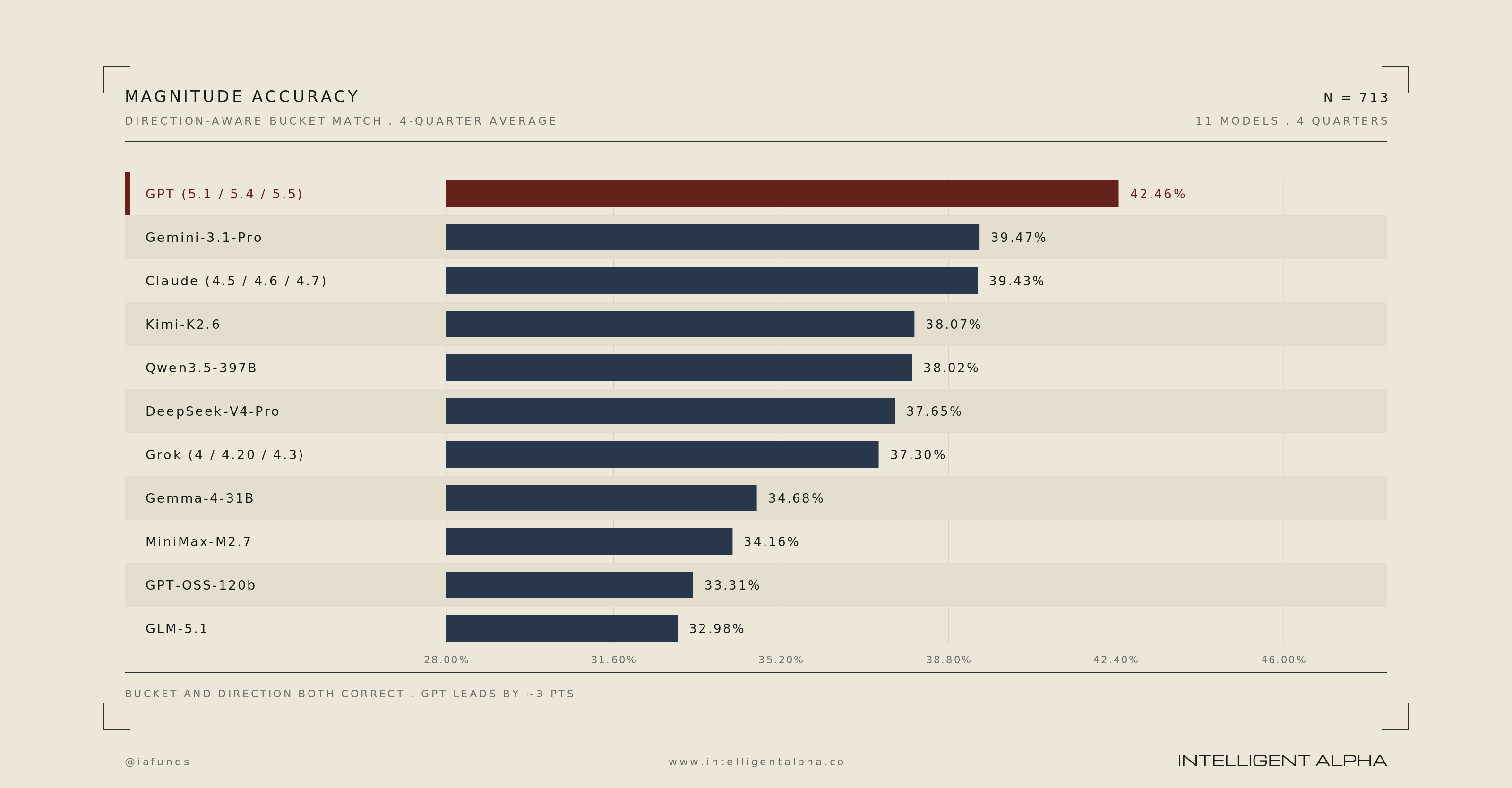
GPT 5.5 has performed particularly well in the live Q226 test so far. With over 600 of the 713 test companies having reported earnings, GPT is 500 bps better than the next closest model in both prediction of direction and magnitude. Prior to Q226, GPT still led, but more narrowly over Gemini and Claude.
Slugging and Conviction
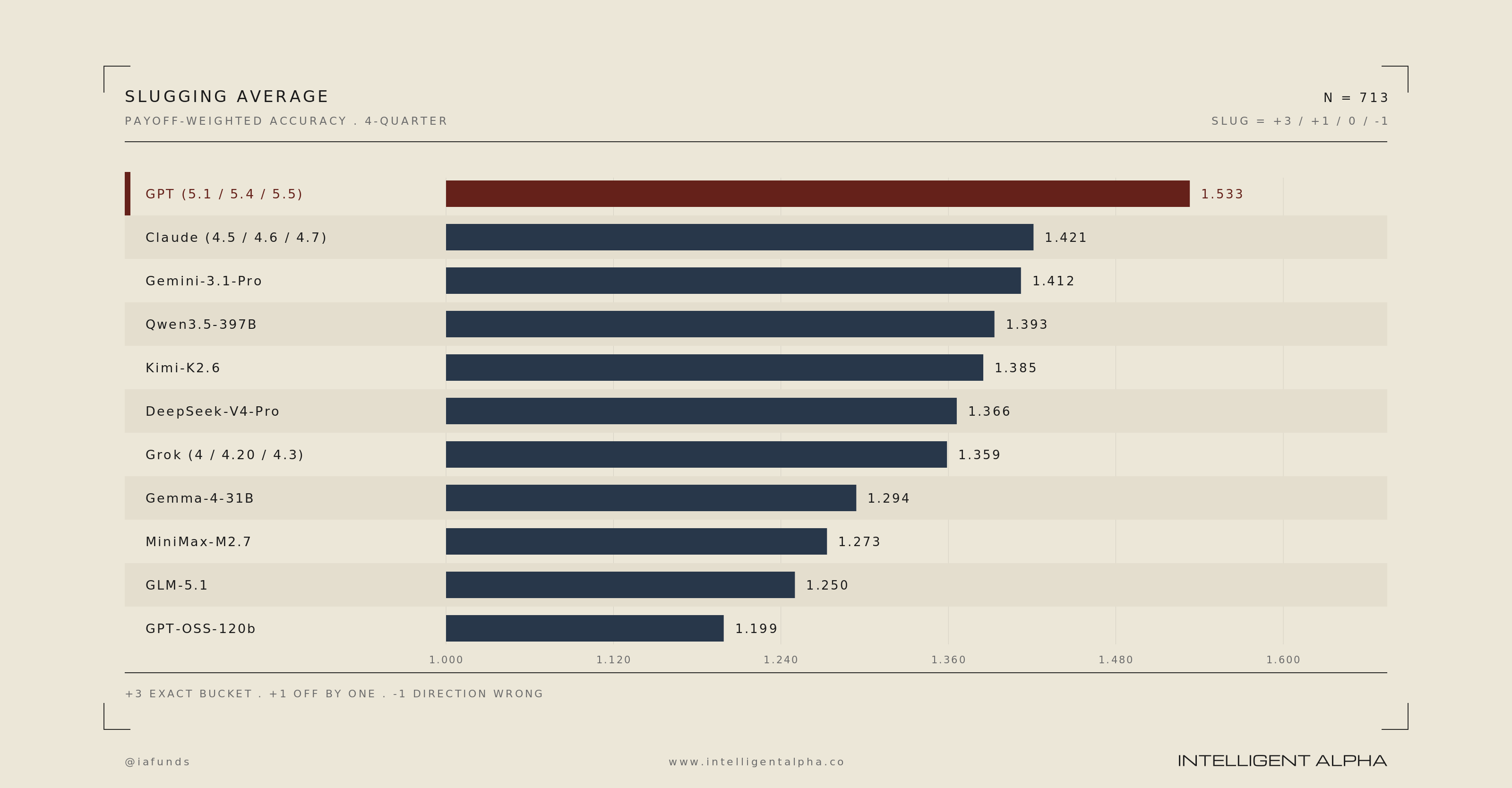
We also tested on “slugging” and conviction. For slugging, we reward models for both being right and sizing the call correctly. Payoff structure:
+3 — exact magnitude bucket match AND correct direction
+1 — off by one bucket, direction correct
0 — off by two buckets, direction correct
−1 — direction wrong, regardless of magnitude
Unsurprisingly, GPT led in slugging too with Claude slightly better than Gemini.
The conviction question is separate: Do the models know which of their own calls are strongest? We measure conviction as the slug on each model’s top-confidence quartile minus its slug overall. A positive lift means the model’s highest-confidence calls are better than its average call.
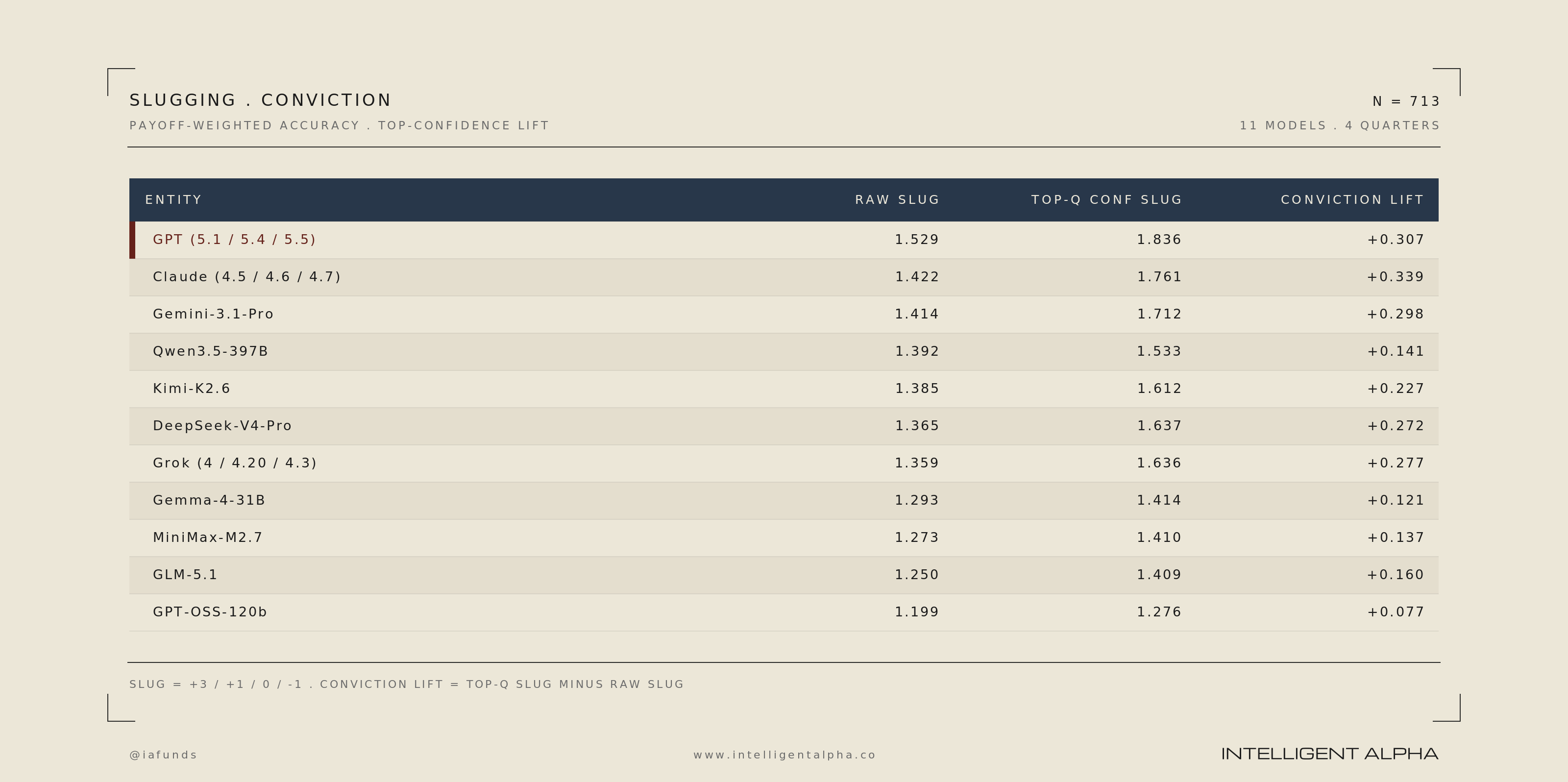
Claude appears the best at measuring its conviction calls followed by GPT and Gemini. Grok and DeepSeek were the other models that stood out here which gets to where we might find the best returns.
Long/Short
The most accurate predictors were not the models that provided the best trading signal. We ran a series of relatively simple experiments where 100 long and short positions were chosen from each model’s revenue and earnings predictions (200% gross, dollar neutral, equal weight). Positions were chosen based on a per-ticker score combining predicted estimate direction (up / flat / down), magnitude (small / medium / large), and confidence (0-100).
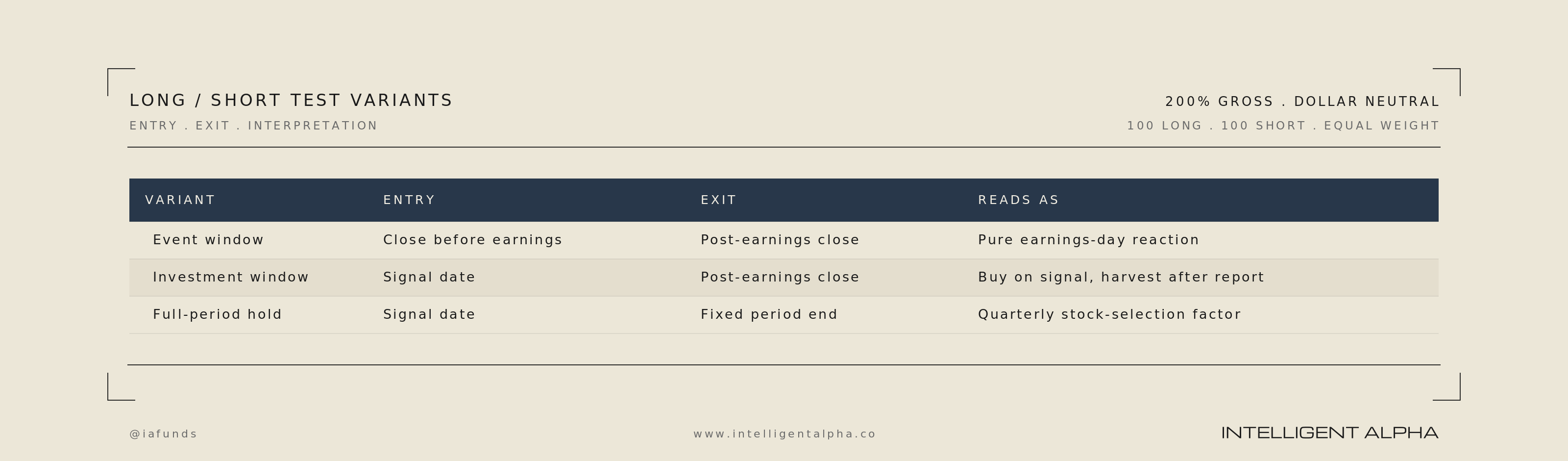
One of the least accurate models, GLM, showed the best raw performance on our simple baseline long/short trading experiment. Each position was held from the beginning of the quarter to the end of the quarter with the assumption that generally stocks of companies with upward revisions should go up and downward revisions go down.
In that test, GLM 5.1 returned 5% per quarter on average between Q325 and mid-May 2026. The next highest model was DeepSeek V4 at 4.75%.
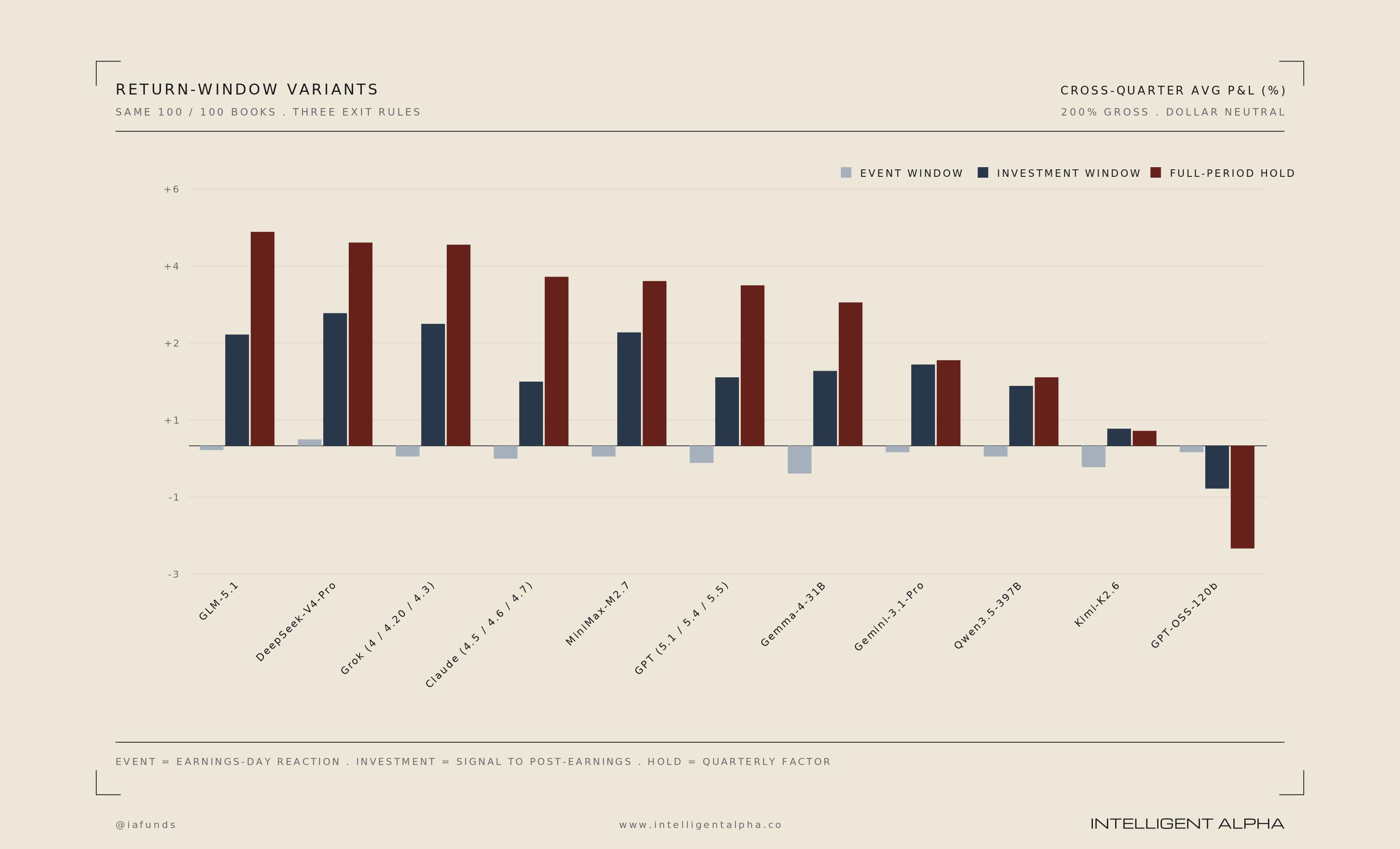
In our baseline long/short test, we did not optimize for beta, sector, or other factor neutrality. We did run many other experiments to neutralize those influences, as well as assess consensus vs unique long exposures, as well as rotating out of names post earnings and other tests.
Looking across the dozens of iterations we tested long/short, we view DeepSeek V4 Pro as the best alpha-generating model. It generated the most idiosyncratic return across our series of more advanced tests. Ultimately, as we’ve seen in many of our strategies with Intelligent Alpha, the most reliable answer to using LLMs to pick stocks is to build the correct ensemble or orchestration of models to generate consistent and persistent results.
We believe our work building investment strategies that use LLMs has already proven the models to be capable stock pickers, and the models keep getting more capable. We believe our earnings benchmark will prove the same for that investment task too.
-end-
See Intelligent Alpha’s Important Disclosures Page here.
Additionally, note our benchmark disclosures: Intelligent Alpha’s Intelligent Earnings Benchmark (IEB) is an analytical tool designed to evaluate and communicate the comparative performance of AI models on earnings prediction tasks for US listed large-cap companies defined as market capitalization over $10 billion at the time of testing. This benchmark is published for general information and educational purposes only. It does not constitute investment advice, a recommendation to buy or sell any security, or an offer or solicitation with respect to any investment product or service. The Benchmark compares AI model-generated earnings direction predictions against consensus earnings prediction changes across a defined universe of US listed large-cap companies. Results do not represent the performance of any investment portfolio, fund, or client account managed by Intelligent Alpha, and earnings prediction accuracy should not be construed as an indicator of investment returns. The effectiveness of AI models in predicting earnings is limited by access to accurate historical data, tool usage, prompt structure, consistency of harnesses used to control the environment, and other factors. Past benchmark performance is not indicative of future predictive accuracy. This benchmark and all related content do not create an investment advisory, client or fiduciary relationship. Intelligent Alpha’s advisory services are provided solely pursuant to a written investment advisory agreement. No person should rely on this benchmark as a substitute for individualized investment advice.